Complément pratique au guide sur les UPS, cet article détaille la mise en œuvre concrète d’un onduleur dans un environnement Linux et Proxmox.
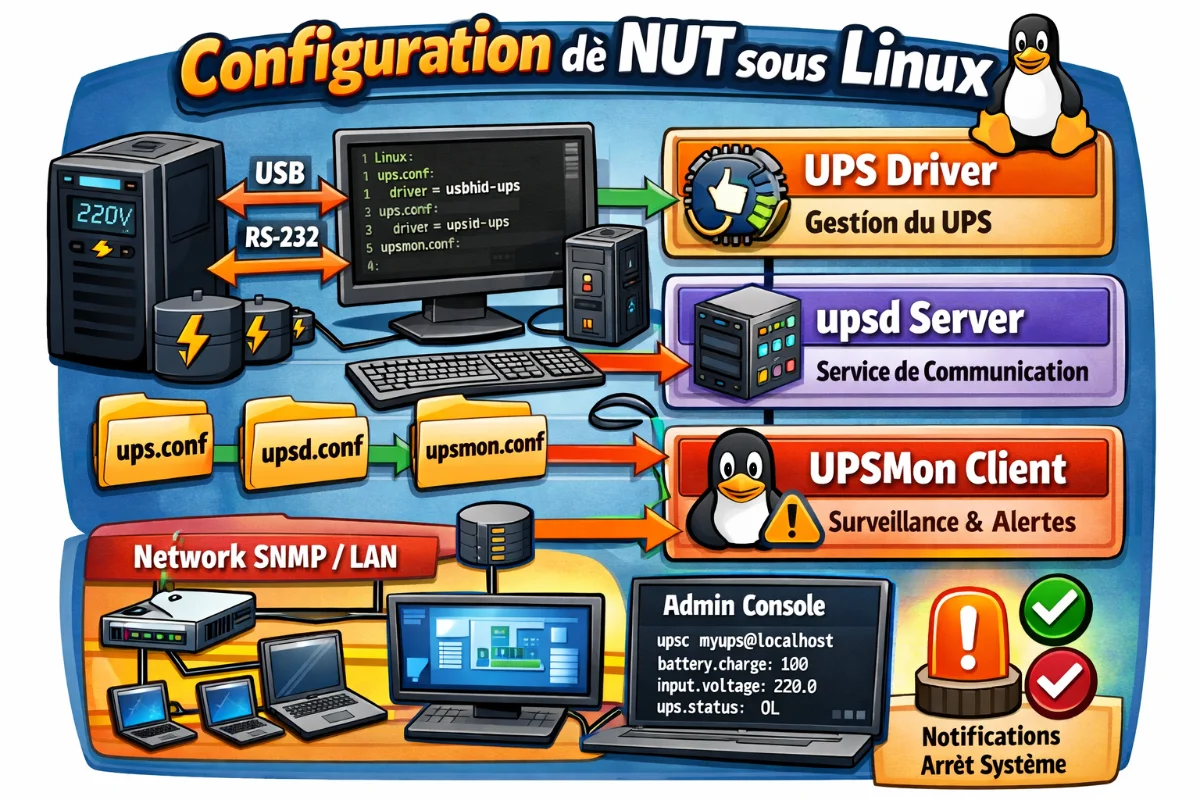
NUT (Network UPS Tools) est la solution de référence pour gérer un UPS sous Linux. C’est un système modulaire qui fonctionne en mode client-serveur.
Architecture de NUT
Installation de NUT
# Debian/Ubuntu
apt update
apt install nut nut-client nut-server
# Vérification de l'installation
nut-scanner -U
Configuration du driver (ups.conf)
Fichier : /etc/nut/ups.conf
# Configuration de l'UPS[myups]
driver = usbhid-ups port = auto desc = « APC Back-UPS Pro 1500 » # Options spécifiques (selon modèle) # vendorid = 051d # productid = 0002
Commandes utiles pour identifier l’UPS :
# Lister les périphériques USB
lsusb | grep -i apc
# Scanner automatiquement
nut-scanner -U
# Tester le driver
upsdrvctl start myups
Configuration du serveur (upsd.conf et upsd.users)
Fichier : /etc/nut/upsd.conf
# Écoute sur toutes les interfaces
LISTEN 0.0.0.0 3493
# Pour écoute locale uniquement
# LISTEN 127.0.0.1 3493
Fichier : /etc/nut/upsd.users
# Utilisateur administrateur[admin]
password = mot_de_passe_securise actions = SET instcmds = ALL upsmon master # Utilisateur pour monitoring distant
[monitor]
password = mot_de_passe_monitoring upsmon slave
Configuration du monitoring (upsmon.conf)
Fichier : /etc/nut/upsmon.conf
# Surveillance de l'UPS local
MONITOR myups@localhost 1 admin mot_de_passe_securise master
# Paramètres d'action
MINSUPPLIES 1
SHUTDOWNCMD "/sbin/shutdown -h +0"
NOTIFYCMD /usr/sbin/upssched
POLLFREQ 5
POLLFREQALERT 5
HOSTSYNC 15
DEADTIME 15
POWERDOWNFLAG /etc/killpower
# Notifications
NOTIFYMSG ONLINE "UPS %s : alimentation secteur rétablie"
NOTIFYMSG ONBATT "UPS %s : fonctionne sur batterie"
NOTIFYMSG LOWBATT "UPS %s : batterie faible"
NOTIFYMSG SHUTDOWN "UPS %s : arrêt système imminent"
NOTIFYFLAG ONLINE SYSLOG+WALL+EXEC
NOTIFYFLAG ONBATT SYSLOG+WALL+EXEC
NOTIFYFLAG LOWBATT SYSLOG+WALL+EXEC
NOTIFYFLAG SHUTDOWN SYSLOG+WALL+EXEC
Configuration du mode NUT
Fichier : /etc/nut/nut.conf
# Mode standalone : serveur et client sur la même machine
MODE=standalone
# Autres modes possibles :
# MODE=netserver # Serveur pour clients distants
# MODE=netclient # Client uniquement
Démarrage et test
# Démarrage des services
systemctl start nut-driver
systemctl start nut-server
systemctl start nut-monitor
# Activation au démarrage
systemctl enable nut-driver
systemctl enable nut-server
systemctl enable nut-monitor
# Vérification du statut
upsc myups
upsc myups battery.charge
upsc myups ups.status
# Test de communication
upscmd -l myups
Surveillance et logs
# Logs NUT
tail -f /var/log/syslog | grep nut
# Statut en temps réel
watch -n 1 'upsc myups'
# Variables disponibles
upsc myups | grep battery
upsc myups | grep input
Intégration d’un UPS avec Proxmox
Proxmox VE intègre nativement la gestion NUT pour l’arrêt automatique des machines virtuelles et conteneurs.
Architecture Proxmox avec UPS
Configuration via l’interface web Proxmox
Configuration manuelle (node master)
Fichier : /etc/nut/ups.conf
[myups]
driver = usbhid-ups
port = auto
desc = "UPS principal Proxmox"
pollinterval = 5
Fichier : /etc/nut/upsd.conf
# Écouter sur le réseau pour les slaves
LISTEN 0.0.0.0 3493
LISTEN ::1 3493
Fichier : /etc/nut/upsd.users
[monuser]
password = VotreMotDePasse
upsmon master
actions = SET
instcmds = ALL
Fichier : /etc/nut/upsmon.conf
MONITOR myups@localhost 1 monuser VotreMotDePasse master
MINSUPPLIES 1
SHUTDOWNCMD "/sbin/shutdown -h +0"
POWERDOWNFLAG /etc/killpower
Configuration des nodes slaves
Sur chaque node Proxmox esclave, configurer uniquement le client :
Fichier : /etc/nut/upsmon.conf
# IP du master = 192.168.1.10
MONITOR myups@192.168.1.10 1 monuser VotreMotDePasse slave
MINSUPPLIES 1
SHUTDOWNCMD "/sbin/shutdown -h +0"
Fichier : /etc/nut/nut.conf
MODE=netclient
Scripts Proxmox pour l’arrêt des VMs
Proxmox gère automatiquement l’arrêt des VMs/CT, mais vous pouvez personnaliser :
Fichier : /usr/local/bin/proxmox-ups-shutdown.sh
#!/bin/bash
# Script d'arrêt personnalisé Proxmox
LOG="/var/log/ups-shutdown.log"
echo "$(date) - Début de la séquence d'arrêt UPS" >> "$LOG"
# Liste toutes les VMs en cours d'exécution
RUNNING_VMS=$(qm list | grep running | awk '{print $1}')
# Arrêt gracieux des VMs
for VM in $RUNNING_VMS; do
echo "$(date) - Arrêt de la VM $VM" >> "$LOG"
qm shutdown $VM
done
# Attendre que toutes les VMs soient arrêtées (max 180 secondes)
TIMEOUT=180
ELAPSED=0
while [ $ELAPSED -lt $TIMEOUT ]; do
RUNNING_COUNT=$(qm list | grep -c running)
if [ $RUNNING_COUNT -eq 0 ]; then
echo "$(date) - Toutes les VMs sont arrêtées" >> "$LOG"
break
fi
sleep 5
ELAPSED=$((ELAPSED + 5))
done
# Arrêt forcé si timeout
if [ $ELAPSED -ge $TIMEOUT ]; then
echo "$(date) - Timeout atteint, arrêt forcé des VMs restantes" >> "$LOG"
for VM in $(qm list | grep running | awk '{print $1}'); do
qm stop $VM
done
fi
# Même chose pour les conteneurs
RUNNING_CTS=$(pct list | grep running | awk '{print $1}')
for CT in $RUNNING_CTS; do
echo "$(date) - Arrêt du conteneur $CT" >> "$LOG"
pct shutdown $CT
done
echo "$(date) - Séquence d'arrêt terminée" >> "$LOG"
# Laisser Proxmox gérer l'arrêt du système
exit 0
chmod +x /usr/local/bin/proxmox-ups-shutdown.sh
Monitoring et notifications
Script de notification par email :
#!/bin/bash
# /usr/local/bin/ups-notify.sh
EVENT=$1
UPS=$2
case $EVENT in
ONBATT)
echo "L'UPS $UPS fonctionne sur batterie" | \
mail -s "ALERTE UPS: Sur batterie" admin@example.com
;;
ONLINE)
echo "L'UPS $UPS est revenu sur secteur" | \
mail -s "INFO UPS: Secteur rétabli" admin@example.com
;;
LOWBATT)
echo "L'UPS $UPS a une batterie faible - Arrêt imminent" | \
mail -s "CRITIQUE UPS: Batterie faible" admin@example.com
;;
esac
Scripts d’arrêt personnalisés pour environnement virtualisé
Au-delà de la configuration standard, des scripts personnalisés permettent un contrôle fin de la séquence d’arrêt.
Architecture d’arrêt intelligent
<svg viewBox="0 0 800 500" xmlns="http://www.w3.org/2000/svg">
<!-- Titre -->
<text x="400" y="25" font-size="16" font-weight="bold" text-anchor="middle" fill="#333">Séquence d'arrêt intelligent avec priorités</text>
<!-- Événement déclencheur -->
<rect x="300" y="60" width="200" height="50" fill="#e74c3c" stroke="#c0392b" stroke-width="2" rx="5"/>
<text x="400" y="90" font-size="13" font-weight="bold" text-anchor="middle" fill="white">COUPURE DÉTECTÉE</text>
<!-- Flèche -->
<path d="M 400 110 L 400 140" stroke="#34495e" stroke-width="3" marker-end="url(#arrow2)"/>
<!-- Phase 1: VMs priorité basse -->
<rect x="50" y="140" width="700" height="70" fill="#f39c12" stroke="#d68910" stroke-width="2" rx="5"/>
<text x="80" y="165" font-size="13" font-weight="bold" fill="white">PHASE 1 - Arrêt VMs priorité BASSE (0-30s)</text>
<text x="80" y="185" font-size="11" fill="white">• VM Dev/Test</text>
<text x="350" y="185" font-size="11" fill="white">• VM temporaires</text>
<text x="580" y="185" font-size="11" fill="white">• Services non-critiques</text>
<!-- Flèche -->
<path d="M 400 210 L 400 240" stroke="#34495e" stroke-width="3" marker-end="url(#arrow2)"/>
<!-- Phase 2: VMs priorité moyenne -->
<rect x="50" y="240" width="700" height="70" fill="#e67e22" stroke="#d35400" stroke-width="2" rx="5"/>
<text x="80" y="265" font-size="13" font-weight="bold" fill="white">PHASE 2 - Arrêt VMs priorité MOYENNE (30-90s)</text>
<text x="80" y="285" font-size="11" fill="white">• Applications web</text>
<text x="350" y="285" font-size="11" fill="white">• Serveurs applicatifs</text>
<text x="580" y="285" font-size="11" fill="white">• Services métier</text>
<!-- Flèche -->
<path d="M 400 310 L 400 340" stroke="#34495e" stroke-width="3" marker-end="url(#arrow2)"/>
<!-- Phase 3: VMs priorité haute -->
<rect x="50" y="340" width="700" height="70" fill="#c0392b" stroke="#a93226" stroke-width="2" rx="5"/>
<text x="80" y="365" font-size="13" font-weight="bold" fill="white">PHASE 3 - Arrêt VMs priorité HAUTE (90-150s)</text>
<text x="80" y="385" font-size="11" fill="white">• Bases de données</text>
<text x="350" y="385" font-size="11" fill="white">• Serveurs de fichiers</text>
<text x="580" y="385" font-size="11" fill="white">• Services critiques</text>
<!-- Flèche -->
<path d="M 400 410 L 400 440" stroke="#34495e" stroke-width="3" marker-end="url(#arrow2)"/>
<!-- Phase finale -->
<rect x="250" y="440" width="300" height="45" fill="#27ae60" stroke="#229954" stroke-width="2" rx="5"/>
<text x="400" y="468" font-size="13" font-weight="bold" text-anchor="middle" fill="white">ARRÊT HYPERVISEUR</text>
<defs>
<marker id="arrow2" markerWidth="10" markerHeight="10" refX="9" refY="3" orient="auto" markerUnits="strokeWidth">
<path d="M0,0 L0,6 L9,3 z" fill="#34495e" />
</marker>
</defs>
</svg>
Script d’arrêt avec priorités
Fichier : /usr/local/bin/smart-ups-shutdown.sh
#!/bin/bash
#=============================================================================
# Script d'arrêt intelligent avec gestion des priorités
# Utilisation: appelé automatiquement par NUT lors d'une coupure
#=============================================================================
LOG="/var/log/smart-ups-shutdown.log"
TIMESTAMP=$(date '+%Y-%m-%d %H:%M:%S')
# Fonction de log
log_message() {
echo "[$TIMESTAMP] $1" >> "$LOG"
logger -t smart-ups-shutdown "$1"
}
# Fonction d'arrêt avec timeout
shutdown_vm_with_timeout() {
local VMID=$1
local TIMEOUT=$2
local VM_NAME=$(qm config $VMID | grep "^name:" | cut -d: -f2 | xargs)
log_message "Arrêt de la VM $VMID ($VM_NAME)"
# Tentative d'arrêt gracieux
qm shutdown $VMID
# Attendre l'arrêt
local ELAPSED=0
while [ $ELAPSED -lt $TIMEOUT ]; do
STATUS=$(qm status $VMID | awk '{print $2}')
if [ "$STATUS" = "stopped" ]; then
log_message "VM $VMID arrêtée avec succès"
return 0
fi
sleep 2
ELAPSED=$((ELAPSED + 2))
done
# Si timeout, arrêt forcé
log_message "Timeout atteint pour VM $VMID - Arrêt forcé"
qm stop $VMID
return 1
}
# Fonction similaire pour les conteneurs
shutdown_ct_with_timeout() {
local CTID=$1
local TIMEOUT=$2
local CT_NAME=$(pct config $CTID | grep "^hostname:" | cut -d: -f2 | xargs)
log_message "Arrêt du conteneur $CTID ($CT_NAME)"
pct shutdown $CTID
local ELAPSED=0
while [ $ELAPSED -lt $TIMEOUT ]; do
STATUS=$(pct status $CTID | awk '{print $2}')
if [ "$STATUS" = "stopped" ]; then
log_message "Conteneur $CTID arrêté avec succès"
return 0
fi
sleep 2
ELAPSED=$((ELAPSED + 2))
done
log_message "Timeout atteint pour conteneur $CTID - Arrêt forcé"
pct stop $CTID
return 1
}
#=============================================================================
# DÉBUT DE LA SÉQUENCE D'ARRÊT
#=============================================================================
log_message "========================================="
log_message "DÉBUT SÉQUENCE D'ARRÊT UPS"
log_message "========================================="
# Définition des priorités (à adapter selon votre configuration)
# Format: VMID:TIMEOUT
# Priorité BASSE (arrêt immédiat, timeout 30s)
PRIORITY_LOW="105:30 106:30 107:30"
# Priorité MOYENNE (arrêt après 30s, timeout 60s)
PRIORITY_MEDIUM="102:60 103:60 104:60"
# Priorité HAUTE (arrêt en dernier, timeout 120s)
PRIORITY_HIGH="100:120 101:120"
# Conteneurs (priorité moyenne généralement)
CONTAINERS="200:60 201:60 202:60"
#=============================================================================
# PHASE 1: Services priorité BASSE
#=============================================================================
log_message "PHASE 1: Arrêt VMs priorité BASSE"
for VM_CONFIG in $PRIORITY_LOW; do
VMID=$(echo $VM_CONFIG | cut -d: -f1)
TIMEOUT=$(echo $VM_CONFIG | cut -d: -f2)
# Vérifier si la VM est en cours d'exécution
STATUS=$(qm status $VMID 2>/dev/null | awk '{print $2}')
if [ "$STATUS" = "running" ]; then
shutdown_vm_with_timeout $VMID $TIMEOUT
fi
done
log_message "Phase 1 terminée - Attente 10 secondes"
sleep 10
#=============================================================================
# PHASE 2: Services priorité MOYENNE + Conteneurs
#=============================================================================
log_message "PHASE 2: Arrêt VMs priorité MOYENNE et Conteneurs"
# VMs priorité moyenne
for VM_CONFIG in $PRIORITY_MEDIUM; do
VMID=$(echo $VM_CONFIG | cut -d: -f1)
TIMEOUT=$(echo $VM_CONFIG | cut -d: -f2)
STATUS=$(qm status $VMID 2>/dev/null | awk '{print $2}')
if [ "$STATUS" = "running" ]; then
shutdown_vm_with_timeout $VMID $TIMEOUT
fi
done
# Conteneurs
for CT_CONFIG in $CONTAINERS; do
CTID=$(echo $CT_CONFIG | cut -d: -f1)
TIMEOUT=$(echo $CT_CONFIG | cut -d: -f2)
STATUS=$(pct status $CTID 2>/dev/null | awk '{print $2}')
if [ "$STATUS" = "running" ]; then
shutdown_ct_with_timeout $CTID $TIMEOUT
fi
done
log_message "Phase 2 terminée - Attente 15 secondes"
sleep 15
#=============================================================================
# PHASE 3: Services priorité HAUTE (critiques)
#=============================================================================
log_message "PHASE 3: Arrêt VMs priorité HAUTE (critiques)"
for VM_CONFIG in $PRIORITY_HIGH; do
VMID=$(echo $VM_CONFIG | cut -d: -f1)
TIMEOUT=$(echo $VM_CONFIG | cut -d: -f2)
STATUS=$(qm status $VMID 2>/dev/null | awk '{print $2}')
if [ "$STATUS" = "running" ]; then
shutdown_vm_with_timeout $VMID $TIMEOUT
fi
done
log_message "Phase 3 terminée"
#=============================================================================
# VÉRIFICATION FINALE
#=============================================================================
log_message "Vérification finale des VMs/CT en cours d'exécution"
STILL_RUNNING_VMS=$(qm list | grep running | wc -l)
STILL_RUNNING_CTS=$(pct list | grep running | wc -l)
if [ $STILL_RUNNING_VMS -gt 0 ]; then
log_message "ATTENTION: $STILL_RUNNING_VMS VM(s) encore en cours d'exécution"
qm list | grep running >> "$LOG"
fi
if [ $STILL_RUNNING_CTS -gt 0 ]; then
log_message "ATTENTION: $STILL_RUNNING_CTS conteneur(s) encore en cours d'exécution"
pct list | grep running >> "$LOG"
fi
#=============================================================================
# FIN
#=============================================================================
log_message "========================================="
log_message "SÉQUENCE D'ARRÊT TERMINÉE"
log_message "L'hyperviseur va maintenant s'arrêter"
log_message "========================================="
exit 0
chmod +x /usr/local/bin/smart-ups-shutdown.sh
Intégration avec NUT
Modifier /etc/nut/upsmon.conf :
# Remplacer la commande d'arrêt par défaut
SHUTDOWNCMD "/usr/local/bin/smart-ups-shutdown.sh && /sbin/shutdown -h +0"
Script de notification avancée
Fichier : /usr/local/bin/ups-notify-advanced.sh
#!/bin/bash
EVENT=$1
UPSNAME=$2
# Configuration
EMAIL="admin@example.com"
WEBHOOK_URL="https://hooks.slack.com/services/YOUR/WEBHOOK/URL"
# Fonction d'envoi vers Slack/Discord
send_webhook() {
local MESSAGE=$1
local COLOR=$2
curl -X POST -H 'Content-type: application/json' \
--data "{\"text\":\"$MESSAGE\",\"username\":\"UPS Monitor\",\"icon_emoji\":\":zap:\"}" \
$WEBHOOK_URL
}
case $EVENT in
ONBATT)
MESSAGE="⚠️ ALERTE: L'UPS $UPSNAME fonctionne sur batterie"
send_webhook "$MESSAGE" "warning"
echo "$MESSAGE" | mail -s "Alerte UPS" $EMAIL
;;
ONLINE)
MESSAGE="✅ INFO: L'UPS $UPSNAME est revenu sur secteur"
send_webhook "$MESSAGE" "good"
;;
LOWBATT)
MESSAGE="🔴 CRITIQUE: Batterie faible sur $UPSNAME - Arrêt imminent!"
send_webhook "$MESSAGE" "danger"
echo "$MESSAGE" | mail -s "URGENT: UPS batterie faible" $EMAIL
;;
SHUTDOWN)
MESSAGE="🛑 ARRÊT: Début de la séquence d'arrêt pour $UPSNAME"
send_webhook "$MESSAGE" "danger"
;;
REPLBATT)
MESSAGE="🔧 MAINTENANCE: La batterie de $UPSNAME doit être remplacée"
send_webhook "$MESSAGE" "warning"
echo "$MESSAGE" | mail -s "UPS: Remplacement batterie nécessaire" $EMAIL
;;
esac
chmod +x /usr/local/bin/ups-notify-advanced.sh
Test de la configuration
# Test du script d'arrêt (sans arrêter réellement)
# Commenter la ligne shutdown dans le script et l'exécuter
/usr/local/bin/smart-ups-shutdown.sh
# Simuler un événement UPS (ne pas faire en production!)
upsmon -c fsd
# Consulter les logs
tail -f /var/log/smart-ups-shutdown.log
tail -f /var/log/syslog | grep nut
Résumé et bonnes pratiques
Checklist de configuration
- Installation et configuration de NUT complète
- Test de communication UPS fonctionnel
- Utilisateurs NUT créés avec mots de passe forts
- Délais d’arrêt adaptés à l’autonomie
- Scripts personnalisés testés en conditions réelles
- Notifications configurées (email, webhooks)
- Documentation des priorités d’arrêt
- Logs régulièrement consultés
- Tests périodiques (tous les 3-6 mois)
Points de vigilance
Délais réalistes : assurez-vous que l’autonomie de la batterie est suffisante pour permettre tous les arrêts séquentiels.
Ordre d’arrêt : respectez les dépendances entre services (bases de données avant applications, etc.).
Firewall : le port 3493 doit être ouvert entre le master et les slaves.
Logs : conservez un historique pour analyser les coupures et ajuster les paramètres.
Maintenance : testez régulièrement le dispositif pour garantir son fonctionnement le jour J.
Cette configuration avancée garantit un arrêt propre et contrôlé de votre infrastructure en cas de coupure électrique, minimisant les risques de corruption et de perte de données.